[Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(1)
결론적으로, 본인은 CNN을 통한 주식 가격의 예측에 실패하였습니다.
Epochs, Batch size 등 과 같은 Hyperparameter (사용자가 입맛(?)대로 설정하는)를 변경하시거나,
CNN을 활용한 다른 주식 가격 예측 전략을 여러분이 직접 구상해보실 수 있을 것이라 믿습니다.
또한, 주식 가격 예측뿐만 아니라, 흉부 x-ray 사진을 통한 폐렴 확진 예측 등
아래 코드에서 주식 부분만 도려내고 여러분이 원하는 이미지 또는 예측 주제를 이식한다면 튜토리얼로서 도움이 될 것입니다.
따라서, 이 글이 딥러닝을 접하시는 많은 분들께 도움이 되었으면 좋겠습니다.
1. 전체 과정 요약
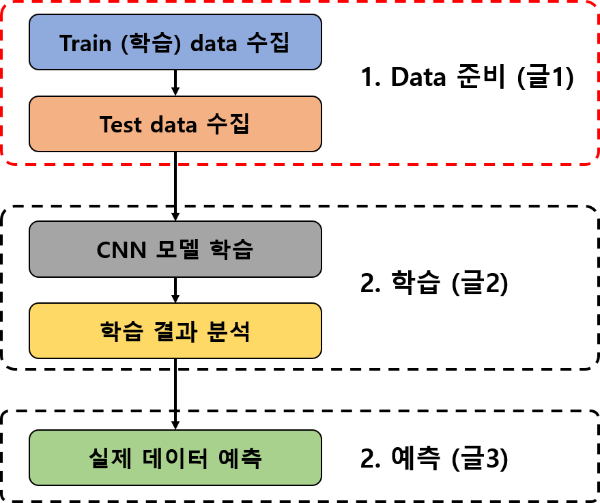
데이터 준비, 학습, 예측의 순서로 총 3번의 글을 작성하였습니다.
[Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(2)
https://sjblog1.tistory.com/66
[Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(2)
1. 전체 과정 요약 데이터 준비, 학습, 예측의 순서로 총 3번의 글을 작성하였습니다. [Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(1) https://sjblog1.tistory.com/65 [Python] 파이썬, 딥러닝 CNN을..
sjblog1.tistory.com
[Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(3)
https://sjblog1.tistory.com/67
[Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(3)
1. 전체 과정 요약 데이터 준비, 학습, 예측의 순서로 총 3번의 글을 작성하였습니다. [Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(1) https://sjblog1.tistory.com/65 [Python] 파이썬, 딥러닝 CNN을..
sjblog1.tistory.com
2. Train data 수집
from pykrx import stock
import pandas as pd
import os
from datetime import datetime, timedelta
import timeOHLC 주가 데이터 수집을 위해 pykrx를 사용하겠습니다.
2-1. 종목명과 종목코드 가져오기
stock_list_stock = pd.DataFrame({'종목코드':stock.get_market_ticker_list(market="ALL")})
stock_list_stock['종목명'] = stock_list_stock['종목코드'].map(lambda x: stock.get_market_ticker_name(x))
stock_list_etf = pd.DataFrame({'종목코드':stock.get_etf_ticker_list(datetime.today().strftime('%Y%m%d'))})
stock_list_etf['종목명'] = stock_list_etf['종목코드'].map(lambda x: stock.get_etf_ticker_name(x))코스피, 코스닥, ETF 종목명과 종목코드를 데이터프레임으로 가져옵니다.
2-2. 해당 종목의 OHLC 주가 데이터 가져오기
def stock_stock(stock_code, stock_from, stock_to):
# 종목
try:
# 주가 데이터 가져오기
df = stock.get_market_ohlcv_by_date(fromdate=stock_from, todate=stock_to, ticker=stock_code)
return df
# ETF
except Exception as ex:
# 주가 데이터 가져오기
df = stock.get_etf_ohlcv_by_date(fromdate=stock_from, todate=stock_to, ticker=stock_code)
return df종목코드에 대한 종목의 OHLC 주가 데이터를 데이터프레임으로 가져옵니다.
함수로 정의하였고, 추후에 Main1에서 불러올 예정입니다.
2-3. OHLC 전처리
def stock_preprocessing(df):
# 칼럼명을 영문명으로 변경
df = df.rename(columns={'시가':'Open', '고가':'High', '저가':'Low', '종가':'Close', '거래량':'Volume'})
df["Close"]=df["Close"].apply(pd.to_numeric,errors="coerce")
df['ma20'] = df['Close'].rolling(window=20).mean() # 20일 이동평균
df['stddev'] = df['Close'].rolling(window=20).std() # 20일 이동표준편차
df['upper'] = df['ma20'] + 2*df['stddev'] # 상단밴드
df['lower'] = df['ma20'] - 2*df['stddev'] # 하단밴드
# 거래정지 시
for i in range(len(df)):
if df['Open'].iloc[i] == 0:
df['Open'].iloc[i] = df['Close'].iloc[i]
df['High'].iloc[i] = df['Close'].iloc[i]
df['Low'].iloc[i] = df['Close'].iloc[i]
df = df.reset_index()
df = df.rename(columns = {'날짜':'Date'})
df = df.set_index('Date')
return dfOHLC 뿐만 아니라, 20일 이동평균과 볼린저밴드를 계산하여 추가합니다.
함수로 정의하였고, 추후에 Main1에서 불러올 예정입니다.
2-4. OHLC 주가 데이터를 .csv로 저장
def save_training(stock_code, stock_from, stock_to):
df_training = stock_stock(stock_code,stock_from,stock_to)
df_training = stock_preprocessing(df_training)
df_training.to_csv('1.stockdatas/' + stock_code + '_training.csv')
time.sleep(0.1)불러온 OHLC 주가 데이터를 "1.stockdatas" 폴더에 엑셀 .csv 파일로 저장합니다.
함수로 정의하였고, 추후에 Main1에서 불러올 예정입니다.
2-5. Main1 실행해봅시다.
# Main1
stock_code = []
stock_from = '20100125'
stock_to = '20211231'
stock_code.append('139260') # TIGER 200 IT
stock_code.append('139220') # TIGER 200 건설
stock_code.append('143860') # TIGER 헬스케어
#stock_code.append('244580') # KODEX 바이오
# Data 저장
os.makedirs('1.stockdatas', exist_ok = True)
for code in stock_code:
save_training(code, stock_from, stock_to)stock_from과 stock_to에 수집할 날짜를 선택해주세요.
stock_code.append('종목코드')에 수집할 종목을 선택해주세요. (더 많이 추가하셔도 됩니다.)
당연히 수집할 날짜가 길수록, 수집할 종목이 많을수록 데이터 전처리와 학습이 오래 걸립니다.
(결과 산출이 목적이 아니라면, 날짜를 1년 단위, 종목은 1~2개 정도로 추천합니다. )
3. Labeling
Labeling은 Class를 나눠 이름을 붙여주는 것입니다.
예를 들어, 동물 이미지를 주고, 이 이미지가 "고양이"냐? "강아지"냐? 라고 물을 때처럼
Class를 "고양이"와 "강아지"로 나눈 것입니다.
그렇다면, 학습을 시키려면 우리는 이미지에 대한 정답을 알고 있어야 하기 때문에
이 이미지는 "고양이", 저 이미지는 "강아지", 또 다른 이미지는 "고양이"
이렇게 정답을 Labeling 즉, 이미지에 정답을 붙여주는 작업입니다.
여기서는, 20일간 OHLC 주가 데이터의 이미지에 대해,
오늘 종가보다, 다음날 종가가 올랐으면 "1", 다음날 종가가 내렸으면 "0"으로 Class를 나누어 Labeling을 하겠습니다.
(이러한 전략은 여러분이 적절하게 수정하시길 추천합니다. 예를 들어, 2% 올랐을 때 "1" 등등)
import os
import pandas as pd
import traceback
3-1. 출력 문자 색상 변경
# 출력문자 색상 변경
formatters = {
'RED': '\033[91m',
'GREEN': '\033[92m',
'END': '\033[0m',
}
3-2. Labeling 생성
def createLabel(stock_code, df, seq_len, filename):
print("Create label begin")
df.fillna(0)
for i in range(0, len(df)):
c = df.loc[i:i + int(seq_len), :]
start_value = 0
end_value = 0
label = ""
if len(c) == int(seq_len)+1:
start_value = c["Close"].iloc[-2]
end_value = c["Close"].iloc[-1]
# 전날 종가에 대하여 다음날 종가가 올랐으면 1, 아니면 0
tmp_value = end_value / start_value
if tmp_value > 1:
label = 1
else:
label = 0
os.makedirs('2.label', exist_ok = True)
with open('2.label/' + stock_code + '_' + filename + '_label_' + str(seq_len) + '.txt', 'a') as the_file:
the_file.write("{}-{},{}".format(stock_code + '_' + filename, i, label))
the_file.write("\n")
print("Create label finished")Labeling 하여 "2.label" 폴더에 .txt파일로 저장합니다.
함수로 정의하였고, 추후에 Main2에서 불러올 예정입니다.
3-3. Main2 실행해봅시다.
print('사용할 windows_length를 입력해주세요. (20)')
windows_length = int(input())
print('사용할 dimension를 입력해주세요. (150)')
dimension = int(input())
i = 0
for code in stock_code:
df_training = pd.read_csv('1.stockdatas/' + code + '_training.csv')
i += 1
try:
# create label training
print('{RED}\nCreate Label Training Data{END}'.format(**formatters))
createLabel(code, df_training, windows_length, 'training')
print('진행: ' + str(i) + '/' + str(len(stock_code)))
print('{GREEN}Create Label Training Data Done\n{END}!'.format(**formatters))
except Exception as ex:
print('createLabel() -> exception!' + str(ex))
print(traceback.format_exc())windows_length는 사용할 OHLC 개수를 설정하며, dimension은 이미지의 크기를 설정합니다.
기본적으로, 20과 150을 입력해줍니다.
4. OHLC를 이미지로 저장
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from mpl_finance import candlestick2_ohlc학습에 사용할 이미지를 만들어 봅시다.
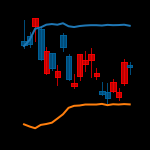
4-1. OHLC 이미지 생성
def ohlc_to_image(stock_code, df, seq_len, dataset_type, dimension):
print("Converting ohlc to candlestick")
os.makedirs('3.dataset/{}_{}/{}/{}'.format(seq_len, dimension,stock_code,dataset_type), exist_ok = True)
df.fillna(0)
plt.style.use('default')
for i in range(0, len(df)):
c = df.loc[i:i + int(seq_len) - 1, :]
c = c.fillna(0)
if i < 19:
continue
if len(c) == int(seq_len):
my_dpi = 96
fig = plt.figure(figsize=(dimension / my_dpi,
dimension / my_dpi), dpi=my_dpi)
ax1 = fig.add_subplot(1, 1, 1)
candlestick2_ochl(ax1, c['Open'], c['Close'], c['High'],c['Low'],
width=1,colorup='#FF0000', colordown='#0067A3')
ax1.grid(False)
ax1.set_xticklabels([])
ax1.set_yticklabels([])
ax1.xaxis.set_visible(False)
ax1.yaxis.set_visible(False)
ax1.axis('off')
ax1.plot(c['Date'], c['upper'], 'g')
#ax1.plot(c['Date'], c['ma20'])
ax1.plot(c['Date'], c['lower'])
ax1.set_facecolor('black')
ax1.figure.set_facecolor('black') # axes 배경색
pngfile = '3.dataset/{}_{}/{}/{}/{}-{}.png'.format(seq_len,dimension,stock_code,dataset_type,stock_code+'_'+dataset_type, i)
fig.savefig(pngfile, pad_inches=0, transparent=False)
plt.close(fig)
# Alpha 채널 없애기 위한
from PIL import Image
img = Image.open(pngfile)
img = img.convert('RGB')
img.save(pngfile)
print("Converting olhc to candlestick finished.")"3.dataset" 폴더에 OHLC 캔들차트 이미지가 저장됩니다.
함수로 정의하였고, 추후에 Main3에서 불러올 예정입니다.
4-2. Main3 실행해봅시다.
i = 0
for code in stock_code:
df_training = pd.read_csv('1.stockdatas/' + code + '_training.csv')
i += 1
try:
# convert to candlestick chart training data
print('{RED}\nConvert Training Data to Candlestick{END}'.format(**formatters))
ohlc_to_image(code, df_training, windows_length, 'training', dimension)
print('진행: ' + str(i) + '/' + str(len(stock_code)))
print('{GREEN}Convert Training Data to Candlestick Done\n{END}'.format(**formatters))
except Exception as ex:
print('ohlc_to_image() -> exception!' + str(ex))
print(traceback.format_exc())
5. 이미지 정리
OHLC 캔들 차트 이미지를 종목코드 단위로 저장하였습니다.
하지만, 우리는 종목코드에 대한 정보는 필요 없고, 이미지만 필요하므로 이미지를 "0"과 "1" Class로 잘 나눠 정리하면 됩니다.
from shutil import copyfile, move
5-1. 이미지 이동
def image_to_dataset(stock_code, dataset_type, label_file):
label_dict = {}
with open(label_file) as f:
for line in f:
(key, val) = line.split(',')
label_dict[key] = val.rstrip()
path = '3.dataset/' + str(windows_length) + '_' + str(dimension) + '/' + stock_code + '/' + dataset_type
for filename in os.listdir(path):
if filename != '' and filename != 'classes':
for k, v in label_dict.items():
splitname = filename.split("_") # [test, training-0.png]
f, e = os.path.splitext(filename) # (test_training-0, .png)
newname = "{}_{}".format(splitname[0], splitname[1])
folders = ['1', '0']
for folder in folders:
os.makedirs('3.dataset/{}_{}/{}/{}/classes/{}'.format(windows_length, dimension,stock_code,dataset_type,folder), exist_ok = True)
for filename in os.listdir(path):
if filename != '' and filename != 'classes':
f, e = os.path.splitext(filename) # (test_training-0, .png)
if f not in label_dict:
print(f+e + '파일이 label에 존재하지 않습니다.')
print('가장 마지막 .png 파일은 사용하지 않습니다.')
continue
if label_dict[f] == "1":
move("{}/{}".format(path, filename),
"{}/classes/1/{}".format(path, filename))
elif label_dict[f] == "0":
move("{}/{}".format(path, filename),
"{}/classes/0/{}".format(path, filename))
print('Done')위에서 .txt에 기록해둔 Labeling을 가져와 이미지를 실제 Labeling에 맞게 "0", "1" 폴더로 이동시킵니다.
5-2. Main4 실행해봅시다.
i = 0
for code in stock_code:
try:
i += 1
print('{RED}\nLabelling Training Data{END}'.format(**formatters))
label_file_training = '2.label/' + code + '_' + 'training' + '_label_' + str(windows_length) + '.txt'
image_to_dataset(code, 'training', label_file_training)
print('진행: ' + str(i) + '/' + str(len(stock_code)))
print('{GREEN}Labelling Training Data Done\n{END}'.format(**formatters))
except Exception as ex:
print('image_to_dataset() -> exception!' + str(ex))
print(traceback.format_exc())
5-3. 최종 이미지
import sys
# 폴더 생성
def create_outputdir(pathdir, targetdir):
os.makedirs("{}/{}".format(pathdir, targetdir), exist_ok = True)
os.makedirs("{}/{}/train/0".format(pathdir, targetdir), exist_ok = True)
os.makedirs("{}/{}/train/1".format(pathdir, targetdir), exist_ok = True)
i = 0
for code in stock_code:
i += 1
pathdir = '3.dataset'
origindir = str(windows_length) + '_' + str(dimension) + '/' + code
targetdir = 'last_dataset_' + code + '_' + str(windows_length) + '_' + str(dimension)
create_outputdir(pathdir, targetdir)
counttest = 0
counttrain = 0
for root, dirs, files in os.walk("{}/{}".format(pathdir, origindir)):
for file in files:
tmp = root.replace('\\','/')
tmp_label = tmp.split('/')[-1]
if tmp_label == '0':
if 'train' in file:
origin = "{}/{}".format(root, file)
destination = "{}/{}/train/0/{}".format(
pathdir, targetdir, file)
copyfile(origin, destination)
counttrain += 1
elif tmp_label == '1':
if 'train' in file:
origin = "{}/{}".format(root, file)
destination = "{}/{}/train/1/{}".format(
pathdir, targetdir, file)
copyfile(origin, destination)
counttrain += 1
print(code, 'Train 데이터 수:', counttrain, '(' + str(i) + '/' + str(len(stock_code)) + ')')
# 합치기
mergedir = 'last_dataset_' + 'merge' + '_' + str(windows_length) + '_' + str(dimension)
os.makedirs("{}/{}".format(pathdir, mergedir), exist_ok = True)
os.makedirs("{}/{}/train/0".format(pathdir, mergedir), exist_ok = True)
os.makedirs("{}/{}/train/1".format(pathdir, mergedir), exist_ok = True)
for filename in os.listdir("{}/{}/train/0".format(pathdir, targetdir)):
move("{}/{}/train/0/".format(pathdir, targetdir) + filename, "{}/{}/train/0".format(pathdir, mergedir))
for filename in os.listdir("{}/{}/train/1".format(pathdir, targetdir)):
move("{}/{}/train/1/".format(pathdir, targetdir) + filename, "{}/{}/train/1".format(pathdir, mergedir))3.dataset/last_dataset_merge_20_150/train/0
3.dataset/last_dataset_merge_20_150/train/1
을 확인하여 모든 OHLC 주가 데이터 이미지가 생성되었는지 확인해봅시다.
6. Test data 수집
Test data 역시 Train과 동일하기 때문에 코드만 올려두겠습니다.
Test data 이미지는
3.dataset/last_dataset_종목코드_20_150/test/0
3.dataset/last_dataset_종목코드_20_150/test/1
을 확인하여 모든 OHLC 주가 데이터 이미지가 생성되었는지 확인해봅시다.
다음 포스팅은 Train, Test 데이터를 이용하여 실제로, CNN 모델에 적용하여 학습을 진행해보겠습니다.
[Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(2)
https://sjblog1.tistory.com/66
[Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(2)
1. 전체 과정 요약 데이터 준비, 학습, 예측의 순서로 총 3번의 글을 작성하였습니다. [Python] 파이썬, 딥러닝 CNN을 이용한 주식 가격 예측(1) https://sjblog1.tistory.com/65 [Python] 파이썬, 딥러닝 CNN을..
sjblog1.tistory.com
from pykrx import stock
import pandas as pd
import os
from datetime import datetime, timedelta
stock_list_stock = pd.DataFrame({'종목코드':stock.get_market_ticker_list(market="ALL")})
stock_list_stock['종목명'] = stock_list_stock['종목코드'].map(lambda x: stock.get_market_ticker_name(x))
stock_list_etf = pd.DataFrame({'종목코드':stock.get_etf_ticker_list(datetime.today().strftime('%Y%m%d'))})
stock_list_etf['종목명'] = stock_list_etf['종목코드'].map(lambda x: stock.get_etf_ticker_name(x))
# 종목 가져오기
def stock_stock(stock_code, stock_from, stock_to):
# 종목
try:
# 주가 데이터 가져오기
df = stock.get_market_ohlcv_by_date(fromdate=stock_from, todate=stock_to, ticker=stock_code)
return df
# ETF
except Exception as ex:
# 주가 데이터 가져오기
df = stock.get_etf_ohlcv_by_date(fromdate=stock_from, todate=stock_to, ticker=stock_code)
return df
# 종목 전처리
def stock_preprocessing(df):
# 칼럼명을 영문명으로 변경
df = df.rename(columns={'시가':'Open', '고가':'High', '저가':'Low', '종가':'Close', '거래량':'Volume'})
df["Close"]=df["Close"].apply(pd.to_numeric,errors="coerce")
df['ma20'] = df['Close'].rolling(window=20).mean() # 20일 이동평균
df['stddev'] = df['Close'].rolling(window=20).std() # 20일 이동표준편차
df['upper'] = df['ma20'] + 2*df['stddev'] # 상단밴드
df['lower'] = df['ma20'] - 2*df['stddev'] # 하단밴드
# 거래정지 시
for i in range(len(df)):
if df['Open'].iloc[i] == 0:
df['Open'].iloc[i] = df['Close'].iloc[i]
df['High'].iloc[i] = df['Close'].iloc[i]
df['Low'].iloc[i] = df['Close'].iloc[i]
df = df.reset_index()
df = df.rename(columns = {'날짜':'Date'})
df = df.set_index('Date')
return df
def save_testing(stock_code, stock_from, stock_to):
df_testing = stock_stock(stock_code,stock_from,stock_to)
df_testing = stock_before(df_testing)
df_testing.to_csv('1.stockdatas/' + stock_code + '_testing.csv')
# ---------------------------------------------------------------------------------- #
# Testing
stock_code = ['252670']
stock_from = '20220101'
stock_to = '20220628'
# ---------------------------------------------------------------------------------- #
# Data 저장
os.makedirs('1.stockdatas', exist_ok = True)
for code in stock_code:
save_testing(code, stock_from, stock_to)
import os
import pandas as pd
import traceback
# 출력문자 색상 변경
formatters = {
'RED': '\033[91m',
'GREEN': '\033[92m',
'END': '\033[0m',
}
def createLabel(stock_code, df, seq_len, filename):
print("Creating label begin")
df.fillna(0)
for i in range(0, len(df)):
c = df.loc[i:i + int(seq_len), :]
start_value = 0
end_value = 0
label = ""
if len(c) == int(seq_len)+1:
start_value = c["Close"].iloc[-2]
end_value = c["Close"].iloc[-1]
# 전날 종가에 대하여 다음날 종가가 올랐으면 1, 아니면 0
tmp_value = end_value / start_value
if tmp_value > 1:
label = 1
else:
label = 0
os.makedirs('2.label', exist_ok = True)
with open('2.label/' + stock_code + '_' + filename + '_label_' + str(seq_len) + '.txt', 'a') as the_file:
the_file.write("{}-{},{}".format(stock_code + '_' + filename, i, label))
the_file.write("\n")
print("Create label finished.")
print('사용할 windows_length를 입력해주세요. (20)')
windows_length = int(input())
print('사용할 dimension를 입력해주세요. (150)')
dimension = int(input())
for code in stock_code:
df_testing = pd.read_csv('1.stockdatas/' + code + '_testing.csv')
try:
# create label testing
print('{RED}\nCreate Label Testing Data{END}'.format(**formatters))
createLabel(code, df_testing, windows_length, 'testing')
print('{GREEN}Create Label Testing Data Done\n{END}!'.format(**formatters))
except Exception as ex:
print('createLabel() -> exception!' + str(ex))
print(traceback.format_exc())
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from mpl_finance import candlestick2_ohlc
def ohlc_to_cs(stock_code, df, seq_len, dataset_type, dimension):
print("Converting ohlc to candlestick")
os.makedirs('3.dataset/{}_{}/{}/{}'.format(seq_len, dimension,stock_code,dataset_type), exist_ok = True)
df.fillna(0)
plt.style.use('default')
for i in range(0, len(df)):
c = df.loc[i:i + int(seq_len) - 1, :]
c = c.fillna(0)
if i < 19:
continue
if len(c) == int(seq_len):
my_dpi = 96
fig = plt.figure(figsize=(dimension / my_dpi,
dimension / my_dpi), dpi=my_dpi)
ax1 = fig.add_subplot(1, 1, 1)
candlestick2_ochl(ax1, c['Open'], c['Close'], c['High'],c['Low'],
width=1,colorup='#FF0000', colordown='#0067A3')
ax1.grid(False)
ax1.set_xticklabels([])
ax1.set_yticklabels([])
ax1.xaxis.set_visible(False)
ax1.yaxis.set_visible(False)
ax1.axis('off')
ax1.plot(c['Date'], c['upper'])
#ax1.plot(c['Date'], c['ma20'])
ax1.plot(c['Date'], c['lower'])
ax1.set_facecolor('black')
ax1.figure.set_facecolor('black') ## axes 배경색
pngfile = '3.dataset/{}_{}/{}/{}/{}-{}.png'.format(seq_len,dimension,stock_code,dataset_type,stock_code+'_'+dataset_type, i)
fig.savefig(pngfile, pad_inches=0, transparent=False)
plt.close(fig)
# Alpha 채널 없애기 위한.
from PIL import Image
img = Image.open(pngfile)
img = img.convert('RGB')
img.save(pngfile)
print("Converting olhc to candlestik finished.")
for code in stock_code:
df_testing = pd.read_csv('1.stockdatas/' + code + '_testing.csv')
try:
# convert to candlestick chart testing data
print('{RED}\nConvert Testing Data to Candlestick{END}'.format(**formatters))
ohlc_to_image(code, df_testing, windows_length, 'testing', dimension)
print('{GREEN}Convert Testing Data to Candlestick Done\n{END}'.format(**formatters))
except Exception as ex:
print('ohlc_to_image() -> exception!' + str(ex))
print(traceback.format_exc())
from shutil import copyfile, move
def image_to_dataset(stock_code, dataset_type, label_file):
label_dict = {}
with open(label_file) as f:
for line in f:
(key, val) = line.split(',')
label_dict[key] = val.rstrip()
path = '3.dataset/' + str(windows_length) + '_' + str(dimension) + '/' + stock_code + '/' + dataset_type
for filename in os.listdir(path):
if filename != '' and filename != 'classes':
for k, v in label_dict.items():
splitname = filename.split("_") # [test, training-0.png]
f, e = os.path.splitext(filename) # (test_training-0, .png)
newname = "{}_{}".format(splitname[0], splitname[1])
folders = ['1', '0']
for folder in folders:
os.makedirs('3.dataset/{}_{}/{}/{}/classes/{}'.format(windows_length, dimension,stock_code,dataset_type,folder), exist_ok = True)
for filename in os.listdir(path):
if filename != '' and filename != 'classes':
# print(filename[:1])
f, e = os.path.splitext(filename) # (test_training-0, .png)
if f not in label_dict:
print(f+e + '파일이 label에 존재하지 않습니다.')
print('가장 마지막 .png 파일은 사용하지 않습니다.')
continue
if label_dict[f] == "1":
move("{}/{}".format(path, filename),
"{}/classes/1/{}".format(path, filename))
elif label_dict[f] == "0":
move("{}/{}".format(path, filename),
"{}/classes/0/{}".format(path, filename))
print('Done')
for code in stock_code:
try:
# labelling data testing
print('{RED}\nLabelling Testing Data{END}'.format(**formatters))
label_file_testing = '2.label/' + code + '_' + 'testing' + '_label_' + str(windows_length) + '.txt'
image_to_dataset(code, 'testing', label_file_testing)
print('{GREEN}Labelling Testing Data Done\n{END}'.format(**formatters))
except Exception as ex:
print('image_to_dataset() -> exception!' + str(ex))
print(traceback.format_exc())
import sys
def create_outputdir(pathdir, targetdir):
os.makedirs("{}/{}".format(pathdir, targetdir), exist_ok = True)
os.makedirs("{}/{}/test/0".format(pathdir, targetdir), exist_ok = True)
os.makedirs("{}/{}/test/1".format(pathdir, targetdir), exist_ok = True)
for code in stock_code:
pathdir = '3.dataset'
origindir = str(windows_length) + '_' + str(dimension) + '/' + code
targetdir = 'last_dataset_' + code + '_' + str(windows_length) + '_' + str(dimension)
create_outputdir(pathdir, targetdir)
counttest = 0
counttrain = 0
for root, dirs, files in os.walk("{}/{}".format(pathdir, origindir)):
for file in files:
tmp = root.replace('\\','/')
tmp_label = tmp.split('/')[-1] # symbol
if tmp_label == '0':
if 'test' in file:
origin = "{}/{}".format(root, file)
destination = "{}/{}/test/0/{}".format(
pathdir, targetdir, file)
copyfile(origin, destination)
counttrain += 1
elif tmp_label == '1':
if 'test' in file:
origin = "{}/{}".format(root, file)
destination = "{}/{}/test/1/{}".format(
pathdir, targetdir, file)
copyfile(origin, destination)
counttrain += 1
print('Test 데이터 수:', counttrain)